HPC for Bioinformatics (3/?): Head Nodes
HPC clusters can be daunting to beginners. This blog post explains the difference of compute and head nodes and goes into detail on head nodes. It explores some trade-offs and the reasoning for different types.
There commonly are two types of nodes that HPC (end) users have access to: compute nodes and head nodes. The compute nodes are the beefy machines with lots of RAM, CPU, maybe even GPUs, and fast network. You can usually not log into them from the outside of the cluster. Rather, you connect to head nodes and this blog post deals with head nodes.
![‘beefy machine as an etching’ according to [Stable Diffusion].](/posts/2023/2023-01-30-beefy-machine.jpg)
‘beefy machine as an etching’ according to [Stable Diffusion].
In the HPC system at BIH, there are three types of head nodes:
- login nodes
- transfer nodes
- the Open OnDemand portal
The Cause for Head Nodes
While cluster administration usually like their users (users are the reason for the system to exist after all), they have some need to restrict what users can and cannot do. One such restriction is putting the cluster machines into a closed network behind a firewall. This firewall will usually block all access except to certain nodes on certain network ports.
There are multiple potential reason for this. One certainly is reducing the “surface” of the system. It is easier to create tight control on fewer systems than on many. In contrast, the network within the cluster might be open and allow users to run servers with “high ports” (above 1024). HPC users may not be experts in securing their applications and putting their open ports behind a firewall is a good idea. Of course, one should not consider all users on the HPC system as fully trustworthy, but at least these protentially problematic services are not accessible from the whole organisation network.
![‘medieval firewall for modern computer systems as an etching’ according to [Stable Diffusion].](/posts/2023/2023-01-30-medieval-firewall.jpg)
‘medieval firewall for modern computer systems as an etching’ according to [Stable Diffusion].
HPC systems often incorporate commercial components such as storage systems. The vendors of these systems may not be terribly quick in providing upgrades in the case that security hole are found. Having a firewall in front of the HPC system creates some containment and at leat the potentially problematic system is only exposed to fewer users that may be considered more trustworthy than “anonymous” users on the organisation network.
Also, the head nodes allow for a more streamlined authentication process. The identity of users is checked here once (e.g., using passwords, SSH keys, or even multi factor authentication). In contrasts, the cluster is considered a single system. Once the identity of the user has been established, users can freely submit jobs or even hop directly to the cluster nodes to inspect what their batch jobs are doing.
Generally, administration blocks users from doing computation on the login nodes as these machines may not be so strong. In fact our HPC system uses relatively weak virtual machines (VM) for the login nodes. This has the advantage that in case of maintenance of the VM’s host, the login VM can be moved to another host without rebooting or even users noticing. We provide two login nodes to our users so in case we need to perform maintenance on the login VM itself (e.g., a kernel upgrade), they can manually switch over to the next.
To summarize, users will connect to the login node via SSH, maybe start a screen or tmux session on there (in case they lose connectivity to the HPC system) and then hop on to other node via the cluster scheduler.
We also keep the available software on the login nodes low and install no computational software or even compilers.
One Node Type to Rule Them All?
So, administration provides two login nodes to their users and everything is well. Until some users decide to upload/download data to/from the HPC system and saturate the network connection to the login node. Now, other users complain that their terminal sessions don’t react any more. Trust me, this happens fairly quickly.
We now have the conflict of aims of “low network latency” for SSH users vs. “high network throughput” for SFTP/rsync users. We resolved this by adding a new head node type: transfer nodes. These are bare metal machines with strong network connectivity that allows users.
![‘a broad highway to a narrow field track as an etching’ (sic!) according to [Stable Diffusion].](/posts/2023/2023-01-30-field-path.jpg)
‘a broad highway to a narrow field track as an etching’ (sic!) according to [Stable Diffusion].
We also provision two of such nodes and allow users to access them from outside of the network. Now, low latency for SSH and high throughput for SFTP/rsync are separated. Again, by providing two nodes users can switch manually between them in case of maintenance. Also, file transfer is usually done from time to time rather than needing a continuous SSH connection for terminals, so the occasional downtime is acceptable.
Lowering the Entry Barrier with Open OnDemand
Now, we can stop and live happily ever after. We can SSH into the cluster via the login nodes and copy files to it and from it via head transfer nodes. However, today’s HPC systems do not only run batch sessions any more. Users want to run RStudio or Jupyter Notebooks and run it backed with beefy CPU machines or even GPUs.
Both softwares are implemented as servers that provide graphical user interfaces to the user via HTTP in the users’ browsers. Traditionally, this would work by submitting a job that starts the server, wait until the job is running and then open an SSH tunnel with remote port forwarding through the head nodes.
![‘remote port forwarding’, taken from [Wikipedia] CC BY-SA-4.0.](/posts/2023/2023-01-30-ssh-tunnel.png)
‘remote port forwarding’, taken from [Wikipedia] CC BY-SA-4.0.
.png){kind=link}
That works very well for experienced users. However, many HPC users are good scientists but might not be so experienced with networks and SSH. The image above shows the syntax for port forwarding and also I always get confused whether the local or remote port is in front or after the host. Also, port forwarding requires the software that you want to run to provide a web interface.
Now, would it not be nice if there was something to help you out here? And there is: Open OnDemand to the rescue!
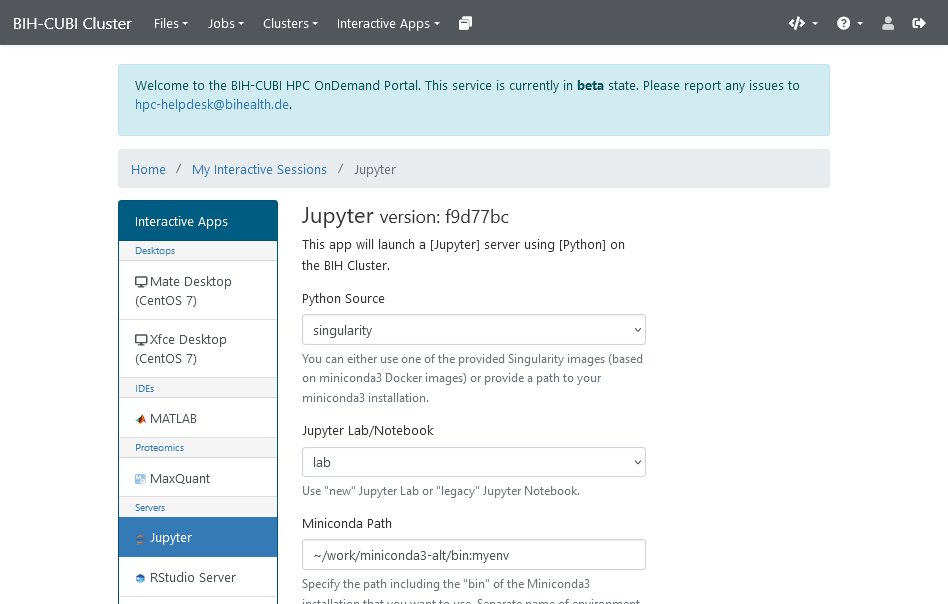
Open OnDemand screen for launching a Jupyter Notebook
Open OnDemand is a software that allows users to securely and conveniently launch jobs with interactive software on HPC systems. It allows administration to provide wrapper scripts, for example, for RStudio and Jupyter. Users can use a graphical interface (as shown in the above picture) to launch jobs. Once the job is running, they can securely connect to the session in their browser.
OnDemand also allows to run classic desktop applications by providing a VNC server for the jobs and provides a VNC client in the browser using TightVNC. This provides functionalit comparable to a virtual desktop infrastructure for your HPC system. This way, it is possible to run the Matlab Desktop software on HPC systems. And while it is not advisable in general, users can also launch a web browser, e.g., to download files directly to the HPC system that can only be downloaded via the web.
Neat!
![’the sky is the limit’ according to [Stable Diffusion].](/posts/2023/2023-01-30-sky-limit.jpg)
’the sky is the limit’ according to [Stable Diffusion].
This works so well that the groups using our cluster even bring the wet-lab bench members to the HPC system where they can modify and run prewritten Jupyter notebooks on their own without the direct help of the computational group members.
Conclusio
To wrap up, we provide three types of head nodes to our users: Login nodes for creating interactive terminal sessions and transfer nodes for high throughput data transfer. We provide two of each in case of maintenance. In addition, the Open OnDemand software allows us to provide users a graphical interface to the cluster and greatly lower the barrier for using HPC resources, e.g., via Jupyter or RStudio.
Thank you for reading.